
MySQL
基礎知識
データベース関連の概念
| 名称 | 内容 | 略称 |
|---|---|---|
| データベース | データを保存する倉庫。データは整理された形で保存される | DataBase(DB) |
| データベース管理システム | データベースを操作、管理するソフトウェア(例:MySQL) | DataBase Management System(DBMS) |
| SQL | リレーショナルデータベースを操作するためのプログラミング言語。統一された標準 | Structured Query Lanquage (SQL) |
SQL 文の分類
- DDL(データ定義言語 Definition):テーブルの作成、削除、変更
- DML(データ操作言語 Manipulation):データの追加、削除、変更
- DQL(データ問い合わせ言語 Query):検索
- DCL(データ制御言語 Control):
grantによる権限付与、revokeによる権限取り消し - TCL(トランザクション制御言語):
commitによるトランザクションのコミット、rollbackによるロールバック
共通構文ルール
- 複数行で書ける。文末はセミコロンにする。
- スペースやインデントを使える。
- 大文字と小文字は区別しない。キーワードは大文字で書くことが推奨される。
- コメント方式: 単行コメント:
--コメント内容、#コメント内容(MySQL 特有)
複数行コメント:/ * コメント内容 * /
データ型
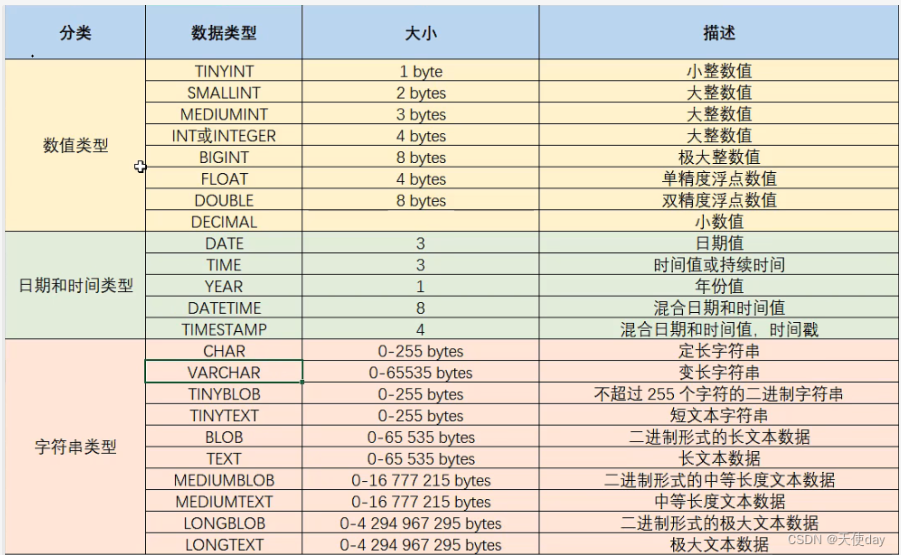
DDL
データベースへ接続する
- スタートメニューで MySQL 8.0 Command Line Client を探して開く。
- cmd ウィンドウで入力する。
mysql [-h 127.0.0.1] [-P 3306] -u root -p yourpasswordデータベース操作
注意:角括弧内の文は省略できます。
- すべてのデータベースを検索する
SHOW DATABASES;- 現在のデータベースを検索する
SELECT DATABASE();- データベースを作成する
CREATE DATABASE [IF NOT EXISTS] database_name [DEFAULT CHARSET 字符集] [COLLATE 排序规则];- データベースを削除する
DROP DATABASE [IF EXISTS] database_name;- データベースを使用 / 入る
USE database_name;テーブル操作
- テーブルを検索する
SHOW TABLES;- テーブル構造を検索する
DESC table_name;- テーブル作成文を検索する
SHOW CREATE TABLE table_name;- テーブルを作成する
CREATE TABLE table_name(
字段1 数据类型1[COMMENT 字段1注释],
字段2 数据类型2[COMMENT 字段2注释],
...
字段n 数据类型n[COMMENT 字段n注释]
);[表注释]テーブルを変更する
- フィールドを追加する
sqlALTER TABLE table_name ADD 字段名 数据类型;- データ型を変更する
sqlALTER TABLE table_name MODIFY 字段名 新字段名;- カラム名とデータ型を変更する
sqlALTER TABLE table_name CHANGE 旧字段名 新字段名 新数据类型;- 一つのカラムを削除する
sqlALTER TABLE table_name DROP 列名;- テーブル名を変更する
sqlALTER TABLE table_name RENAME TO 新表名;テーブルを削除する
DROP TABLE [IF EXISTS] table_name;テーブルを削除し、同じテーブルを再作成する。
TRUNCATE TABLE table_name;DML
データを追加する
- 指定したフィールドにデータを追加する
INSERT INTO table_name (字段名1,字段名2,...) VALUES (值1,值2,..);- 一行のデータを追加する
INSERT INTO table_name VALUES (值1,值2,.….);- 指定したフィールドへ複数データを追加する
INSERT INTO table_name (字段名1,字段名2,...) VALUES (值1,值2,...),(值1,值2,..….);- すべてのフィールドへ複数データを追加する
INSERT INTO table_name VALUES (值1,值2,...) , (值1,值2,...);注意:
- データを挿入するとき、フィールドの順序は値の順序と一致させる必要がある
- 文字列と日付型データは引用符で囲む
データを変更する
UPDATE table_name SET 字段名1 = 值1,字段名2 = 值2,.... [WHERE条件];データを削除する
DELETE FROM table_name [WHERE条件];注意: 条件を追加しない場合、データはすべて削除されます。
DQL
基本検索
SELECT 字段列表 FROM 表名;- 返されるフィールドに別名を付ける
SELECT 字段1 [AS] '别名1' FROM 表名;- 重複レコードを取り除く
SELECT DISTINCT 字段列表 FROM table_name;注意
DISTINCTはすべてのフィールドの直前にだけ置ける- カラム名が複数ある場合、すべてのフィールドが完全に同じ場合だけ重複除去される
例:
--岗位数量を集計する
SELECT count(DISTINCT job) FROM emp;条件検索
SELECT 字段列表 FROM table_name WHERE 条件列表;条件検索を理解する前に、まず mysql の基本的な 演算子 を確認します。
| 演算子分類 | 演算子 | 意味 |
|---|---|---|
| 算術演算子 | +、-、*、/、% | Java と同じ意味 |
| 比較演算子 | =、>、<、>=、<=、<>または!= | <> も「等しくない」を表す |
| 比較演算子 | IS NULL、IS NOT NULL、IN、BETWEEN AND | NULL である、NULL ではない、条件内にある、条件範囲内にある |
| 論理演算子 | AND または &&、OR または ll、NOT または ! | AND、OR、NOT |
あいまい検索: LIKE + プレースホルダー
| プレースホルダー | 意味 |
|---|---|
| _(アンダースコア) | 任意の一文字にマッチする |
| % | 任意の複数文字にマッチする |
例:
empの中で年齢が 15 歳から 20 歳までのデータを検索する
SELECT * FROM emp WHERE age BETWEEN 15 AND 20;empの中で姓が張の人の情報を検索する
--姓が張である人を探せばよいので、プレースホルダー%を直接使う
SELECT * FROM emp WHERE name LIKE '张%';集約関数
一列のデータを一つの全体として扱い、縦方向に計算します。
| 関数名 | 意味 |
|---|---|
| COUNT | 件数を集計する |
| MAX | 最大値 |
| MIN | 最小値 |
| AVG | 平均値 |
| SUM | 合計 |
構文:
SELECT 聚合函数(字段列表) FROM table_name;NULL はすべての集約関数の計算に参加しません。
例:
emp 社員テーブル内の社員数を集計する。
SELECT COUNT(*) FROM emp;グループ検索
構文:
SELECT 字段列表 FROM table_name [WHERE条件] GROUP BY 分组字段名 [HAVING 分组后过滤条件];WHERE と HAVING の違い
- 実行タイミングが違う:
whereはグループ化の前にフィルタリングを行う。where条件を満たさないデータはグループ化に参加しない。一方、havingはグループ化後の結果をフィルタリングする。 - 判定条件が違う:
whereでは集約関数を判定できないが、havingではできる。
例:
emp で年齢が 45 未満の社員を検索し、住所でグループ化し、社員数が 3 以上の住所を取得する。
--分解して理解する。まず年齢が45未満の社員数を検索する
SELECT COUNT(*) FROM emp WHERE age < 45;
--次に住所ごとにグループ化する
SELECT COUNT(*) FROM emp WHERE age < 45 GROUP BY address;
--最後に社員数が3以上の住所を絞り込む
SELECT COUNT(*) FROM emp WHERE age < 45 GROUP BY address HAVING COUNT(*) >= 3;実行順序:where > 集約関数 > having
グループ化後、検索するフィールドは通常、集約関数とグループ化フィールドです。他のフィールドを検索しても意味はありません。
ソート検索
構文:
SELECT 字段列表 FROM table_name ORDER BY 字段1 排序方式1,字段2 排序方式2;ソート方式:
- ASC 昇順(デフォルト)
- DESC 降順
注意:複数フィールドでソートする場合、最初のフィールド値が同じときだけ、二つ目のフィールドでソートされます。
ページング検索
構文:
SELECT 字段列表 FROM table_name LIMIT 起始索引 , 查询记录数;注意:
- 開始インデックスは 0 から始まる。
起始索引= (查询页码-1) *每页显示记录数。 - ページング検索はデータベースによって実装が異なる。MySQL では
LIMITを使う。 - 1 ページ目のデータを検索する場合、開始インデックスは省略でき、
LIMIT 查询记录数と簡略化できる。
DCL
DCL の正式名称は Data Control Language(データ制御言語)です。データベースユーザーの管理と、データベースアクセス権限の制御に使います。
この種類の SQL は開発者が操作することは少なく、主に DBA(Database Administrator、データベース管理者)が使います。
ユーザー管理
- ユーザーを検索する
USE mysql;
SELECT * FROM user;- ユーザーを作成する
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
# どのホストからでもデータベースへアクセスできるようにする場合は '用户名'@'%' を使う- ユーザーパスワードを変更する
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';- ユーザーを削除する
DROP USER '用户名'@'主机名';権限制御
| 権限タイプ | 具体的な権限 | 権限説明 |
|---|---|---|
| すべての権限 | ALL, ALL PRIVILEGES | すべての権限を持つ |
| 検索権限 | SELECT | データを検索する |
| 挿入権限 | INSERT | データを挿入する |
| 更新権限 | UPDATE | データを変更する |
| 削除権限 | DELETE | データを削除する |
| テーブル構造変更権限 | ALTER | テーブルを変更する |
| オブジェクト削除権限 | DROP | データベース / テーブル / ビューを削除する |
| オブジェクト作成権限 | CREATE | データベース / テーブルを作成する |
- 権限を検索する
SHOW GRANTS FOR '用户名'@'主机名';- 権限を付与する
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';- 権限を取り消す
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';複数テーブル検索
まず、この章で使うテーブル構造を確認します。
CREATE TABLE student (
id INT PRIMARY KEY,
name VARCHAR(50),
class_id INT,
-- 其他字段...
FOREIGN KEY (class_id) REFERENCES class(id)
);
CREATE TABLE class (
id INT PRIMARY KEY,
name VARCHAR(50),
-- 其他字段...
);テーブル同士の関係
- 一対多
- 一つのクラスには複数の学生がいる
- 一人の学生は一つのクラスに対応する
- 多対多
- 一人の学生は複数の科目を選択できる
- 一つの科目は複数の学生に選択される
- 一対一
- 学生と学生詳細情報テーブル
- 単一テーブルの分割でよく使う。一つのテーブルの基本フィールドを一つのテーブルに置き、その他の詳細フィールドを別のテーブルに置く
たとえば、学生テーブルとその所属クラスの二つのテーブルを検索するとき、次のように直接書くとします。
SELECT * FROM student , class;返される結果数は、student の件数と class の件数を掛けた数になります。
この現象を デカルト積 と呼びます。
そのため、不要なデータを消し、有効なデータを残す 必要があります。
検索方式の分類
複数テーブル検索は次のように分けられます。
- 結合検索
A、B 二つのテーブルの共通部分データを検索するものを内部結合と呼びます。
A のすべてのデータを検索し、同時に A、B の共通部分データも検索するものを左外部結合と呼びます。
同じように、B 側を基準にする右外部結合もあります。
テーブル自身と結合検索する場合は、自己結合と呼びます。
注意:自己結合では同じテーブルを使うため、別名を付ける必要があります。
- サブクエリ
内部結合
暗黙的内部結合
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件...;
例:暗黙的内部結合を使って、学生名とそのクラス名を検索する。
SELECT student.name,class.name FROM student , class WHERE student.class_id = class.id;明示的内部結合
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件...;
同じ例を明示的内部結合で書く。
SELECT student.name,class.name FROM student INNER JOIN class ON student.class_id = class.id;外部結合
左外部結合
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件...;
例:すべての学生とその所属クラス名を検索する。クラスが割り当てられていない学生も含める。
SELECT student.name FROM student LEFT OUTER JOIN class ON student.class_id = class.id;右外部結合
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON条件...;
- 注意:
MySQL では、実際には右外部結合 RIGHT OUTER JOIN を直接サポートしない場合があります。ただし、検索内のテーブル順序を調整し、左外部結合 LEFT OUTER JOIN を使えば、右外部結合と同じ効果を再現できます。
自己結合
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件...;
例:同じクラスにいる学生を探す。
SELECT
s1.name AS student1,
s2.name AS student2
FROM student s1
JOIN student s2
ON s1.class_id = s2.class_id
WHERE s1.id < s2.id;--重複と自分自身とのマッチを避けるUNION 検索
概念:
二つ以上の SELECT 文の結果セットを一つの結果セットにまとめられます。
各 SELECT 文は UNION 演算子の前に置き、すべての SELECT 文は同じ列を持つ必要があります。
分類:
UNION ALLはすべてのデータをそのまま結合するUNIONは結合後のデータから重複を取り除く
例:すべての学生名とすべてのクラス名を検索し、この二つの結果セットを一つのリストにまとめる。
-- すべての学生名を検索する
SELECT name
FROM student
UNION
-- すべてのクラス名を検索する
SELECT name
FROM class;サブクエリ / ネスト検索
--外側は
INSERT、UPDATE、SELECTにできる
SELECT * FROM 表1 WHERE 字段1 = (SELECT 字段1 FROM 表2);
例:
-- 少なくとも一人の学生がいるクラスを探す
SELECT name
FROM class
WHERE id IN (
SELECT DISTINCT class_id
FROM student
);サブクエリの結果によって、さらに次のように分けられます。
- スカラーサブクエリ(サブクエリ結果が単一値)
- 列サブクエリ(サブクエリ結果が一列)
- 行サブクエリ(サブクエリ結果が一行)
- 表サブクエリ(サブクエリ結果が複数行、複数列)
演算子
ANY(SOME):サブクエリが返すリストの中で、一つでも条件を満たせばよいALL:すべてを満たす必要がある
関数
数値関数
- 切り上げ
CEIL(x)
- 切り下げ
FLOOR(x)
- x/y の余りを返す
MOD(x,y)
- 0〜1 の乱数を返す
RAND()
- 引数 x を四捨五入し、y 桁の小数を保持する
ROUND(x,y)
文字列関数
| 関数名 | 関数形式 | 関数機能 |
|---|---|---|
| 文字列結合関数 | CONCAT(S1,S2....Sn) | S1、S2、...、Sn を一つの文字列に結合する |
| 小文字変換関数 | LOWER(str) | 文字列 str をすべて小文字に変換する |
| 大文字変換関数 | UPPER(str) | 文字列 str をすべて大文字に変換する |
| 左埋め関数 | LPAD(str,n,pad) | 文字列 pad で str の左側を埋め、長さを n 文字にする |
| 右埋め関数 | RPAD(str,n,pad) | 文字列 pad で str の右側を埋め、長さを n 文字にする |
| 前後空白削除関数 | TRIM(str) | 文字列 str の先頭と末尾の空白を取り除く |
| 文字列切り出し関数 | SUBSTRING(str,start,len) | 文字列 str の start 位置から len 文字分を返す |
日付関数
- 現在の日付を返す
CURDATE()
- 現在の時刻を返す
CURTIME()
- 現在の日付と時刻を返す
NOW()
- 指定した
dateの年を取得する
YEAR(date)
- 指定した
dateの月を取得する
MONTH(date)
- 指定した
dateの日を取得する
DAY(date)
- 日付 / 時刻値に時間間隔
experを加えた後の時間値を返す
DATE_ADD(date, INTERVAL expr type)
- 開始時間
date1と終了時間date2の間の日数を返す
DATEDIFF(date1,date2)
フロー関数
- value が true の場合は t を返し、そうでなければ f を返す
lF(value , t , f)
- value1 が NULL でなければ value1 を返し、そうでなければ value2 を返す
IFNULL(value1 , value2)
- val1 が true の場合は res1 を返し、... そうでなければ default のデフォルト値を返す
CASE WHEN [vall] THEN [res1] ...ELSE [default] END
- expr の値が val1 と等しい場合は res1 を返し、... そうでなければ default のデフォルト値を返す
CASE [expr] WHEN [vall] THEN [res1] ...ELSE [default] END
制約
概念
- 制約はフィールドに作用するルールであり、テーブルに保存されるデータを制限するために使います。
- 目的は、データベース内のデータの正確性、有効性、完全性を保証することです。
分類
| 名称 | キーワード | 意味 |
|---|---|---|
| 非 NULL 制約 | NOT NULL | このフィールドは NULL にできない |
| 一意制約 | NUIQUE | このフィールドは重複内容を持てない |
| 主キー制約 | PRIMARY KEY | 主キーは一行データの一意な識別子であり、非 NULL かつ一意である必要がある |
| デフォルト制約 | DEFAULT | データ保存時にこのフィールドの値を指定しない場合、デフォルト値を使う |
| チェック制約 | CHECK | (8.0.16 以降)フィールド値がある条件を満たすことを保証する |
| 外部キー制約 | FOREIGN KEY | 下で重点的に説明する |
注意:制約はフィールドに作用し、テーブル作成 / 変更時に追加します。
使用例:
CREATE TABLE table_name (
column1 datatype PRIMARY KEY,
column2 datatype UNIQUE,
column3 datatype NOT NULL,
column4 datatype CHECK (condition),
column5 datatype DEFAULT value,
column6 datatype,
...
);外部キー制約
役割:二つのテーブルのデータ間に接続を作り、データの一貫性と完全性を保証します。
外部キーを追加する
- 方式一
CREATE TABLE table_name(
字段名 数据类型,
[CONSTRAINT][外键名称] FOREIGN KEY(外键字段名)
REFERENCES 主表名(主表列名)
);- 方式二
ALTER TABLE table_name ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名);外部キーを削除する
構文:
ALTER TABLE table_name DROP FOREINGN KEY 外键名;外部キーの削除 / 更新動作
NO ACTION / RESTRICT
親テーブル で対応するレコードを 削除 / 更新 するとき、まずそのレコードに対応する 外部キー があるかを確認します。ある場合は 削除 / 更新を許可しません。
CASCADE
親テーブル で対応するレコードを 削除 / 更新 するとき、まずそのレコードに対応する外部キーがあるかを確認します。ある場合は、子テーブル内の外部キーに対応するレコードも削除 / 更新します。
SET NULL
親テーブル で対応するレコードを 削除 するとき、まずそのレコードに対応する外部キーがあるかを確認します。ある場合は 子テーブル内のその外部キー値を null に設定します。この外部キーは null を許可する必要があります。
SET DEFAULT
親テーブル に変更があったとき、子テーブルは 外部キー列をデフォルト値に設定します(InnoDB はサポートしません)。
使用方法
ALTER TABLE table_name
ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段)
REFERENCES 主表名(主表字段名)
ON UPDATE CASCADE
ON DELETE CASCADE;以下は、この SQL の詳しい説明です。
ALTER TABLE table_name:
このコマンドは、すでに存在するテーブル(table_name)を変更するために使います。
ADD CONSTRAINT 外键名称
このコマンドは、テーブルに新しい制約を追加し、その制約に名前(外部キー名)を指定するために使います。ここでの「外部キー名」はプレースホルダーなので、具体的な外部キー制約名に置き換える必要があります。
FOREIGN KEY (外键字段)
この部分は、どのフィールドを外部キーとして使うかを指定します。外部キーフィールドはプレースホルダーなので、実際の外部キーフィールド名に置き換える必要があります。
REFERENCES 主表名(主表字段名)
この部分は、外部キーがどのテーブル(親テーブル名)とどのフィールド(親テーブルフィールド名)を参照するかを指定します。親テーブル名と親テーブルフィールド名はどちらもプレースホルダーなので、実際の名前に置き換える必要があります。
ON UPDATE CASCADE
これは、親テーブル内の親テーブルフィールドの値が更新されたとき、外部キーテーブル内の対応する外部キーフィールドの値も更新されるべきだと指定します。CASCADE はカスケード操作を表し、親テーブルフィールドの更新が自動で外部キーフィールドへ伝わります。
ON DELETE CASCADE
これは、親テーブル内のレコードが削除されたとき、外部キーテーブル内でそのレコードを参照しているすべての外部キーフィールドを持つレコードも削除されるべきだと指定します。同じく、CASCADE はカスケード操作を表し、親テーブルレコードの削除が自動で外部キーテーブルへ伝わります。
トランザクション
概念
トランザクションは一連の操作の集合です。トランザクションはすべての操作を一つの全体としてシステムへコミット、または取り消します。つまり、これらの操作は、エラーが発生した場合、すべて成功するか、すべて失敗します。
MySQL では、デフォルトでトランザクションは自動コミットされます。これは、INSERT、UPDATE、DELETE などのデータ操作言語(DML)文を実行すると、MySQL がすぐに暗黙的にトランザクションをコミットするという意味です。この自動コミットの動作は、場合によってはデータ不一致や意図しない結果につながる可能性があります。
トランザクションコミット方式の確認 / 設定
SELECT @@autocommit;:現在の自動コミット設定を確認するために使います。戻り値が1の場合は自動コミットが有効、0の場合は自動コミットが無効です。SET @@autocommit=0;:自動コミットを無効に設定します。自動コミットを無効にした後は、COMMITでトランザクションをコミットするか、ROLLBACKでロールバックして、トランザクションの終了を手動で制御する必要があります。
トランザクションを開始する:
START TRANSACTIONまたはBEGIN;:この二つの文は新しいトランザクションを開始するために使います。トランザクション開始後、後続のデータベース操作は、トランザクションがコミットまたはロールバックされるまで、トランザクションの一部として扱われます。
トランザクションをコミットする:
COMMIT;:トランザクション内のすべての操作が正常に実行された後、COMMIT文でトランザクションをコミットできます。コミット後、トランザクション内のデータベース変更は永久に保存されます。
トランザクションをロールバックする:
ROLLBACK;:トランザクション実行中にエラーが発生した場合、またはトランザクション内の操作を取り消したい場合、ROLLBACK文でトランザクションをロールバックできます。ロールバックすると、トランザクション内のデータベース変更はすべて取り消され、データベースはトランザクション開始前の状態に戻ります。
トランザクションの特性
- 原子性(Atomicity):
トランザクションは分割できない最小の操作単位です。すべて成功するか、すべて失敗します。つまり、トランザクション内のどれか一つの操作が失敗した場合、トランザクション全体がロールバックされます。まるでそのトランザクションが一度も発生しなかったようになります。たとえば銀行振込のトランザクションでは、一つの口座から金額を引く操作と、別の口座へ金額を追加する操作は、同時に成功または同時に失敗しなければなりません。一部だけ完了することはできません。
- 一貫性(Consistency):
トランザクション完了時、すべてのデータは一貫した状態を保つ必要があります。つまり、トランザクションの実行はデータベースの完全性制約と業務ルールに従う必要があります。たとえば、あるテーブルのフィールドに一意制約が定義されている場合、トランザクション内で挿入するデータはその一意制約に違反してはいけません。トランザクション内の操作が一貫性要件に違反した場合、データベースシステムはトランザクションをロールバックし、データの一貫性を保証します。
- 分離性(Isolation):
データベースシステムが提供する分離メカニズムにより、トランザクションは外部の並行操作の影響を受けない独立した環境で実行されます。異なるトランザクションは互いに分離され、干渉しないべきです。ただし、並行トランザクションが存在するため、ダーティリード、ノンリピータブルリード、ファントムリードなどの問題が発生する可能性があります。これらの問題を解決するために、データベースシステムは異なるトランザクション分離レベルを提供しています。
- 永続性(Durability):
トランザクションが一度コミットまたはロールバックされると、データベース内のデータへの変更は永久的になります。つまり、データベースシステムに障害が発生しても、すでにコミットされたトランザクションの結果は失われません。データベースシステムは通常、ログやバックアップなどの技術を使って、トランザクションの永続性を保証します。
並行トランザクションによって起きる問題
- ダーティリード
あるトランザクションが、別のトランザクションでまだコミットされていないデータを読み取ることです。たとえば、トランザクション A が一つのデータを変更したがまだコミットしていないとき、トランザクション B がその変更済みデータを読み取ったとします。もしトランザクション A が最終的にその変更をロールバックした場合、トランザクション B が読み取ったデータは「汚いデータ」です。本来データベースに存在すべきではないためです。
- ノンリピータブルリード
一つのトランザクションが同じレコードを前後で読み取ったとき、二回の読み取り結果が異なることをノンリピータブルリードと呼びます。たとえば、トランザクション A が一つのデータを読み取り、その後トランザクション B がそのデータを変更してコミットします。この時点でトランザクション A が再度同じデータを読み取ると、二回の読み取り結果が異なります。
- ファントムリード
あるトランザクションが条件に従ってデータを検索したとき、対応するデータ行がなかったのに、データを挿入しようとすると、その行がすでに存在しているように見える現象です。たとえば、トランザクション A がある条件でデータを検索し、条件に合う行を見つけられなかったとします。その後、トランザクション B がその条件に合うデータを挿入してコミットします。この時点でトランザクション A が同じ条件で再度検索すると、先ほどトランザクション B が挿入したデータ行を発見します。
トランザクション分離レベル
上の問題を解決するために使います。
- Read uncommitted(未コミット読み取り)
この分離レベルでは、一つのトランザクションが別のトランザクションの未コミットデータを読み取れます。そのため、ダーティリード、ノンリピータブルリード、ファントムリードがすべて発生する可能性があります。この分離レベルは最も高い並行性能を提供できますが、データ不一致のリスクが高いため、実際のアプリケーションでは通常おすすめされません。
- Read committed(コミット済み読み取り)
この分離レベルでは、一つのトランザクションは別のトランザクションがすでにコミットしたデータだけを読み取れます。ダーティリードは避けられますが、ノンリピータブルリードとファントムリードはまだ発生する可能性があります。この分離レベルは多くのデータベースシステムでデフォルトの分離レベルです。一定のデータ一貫性と比較的よい並行性能を提供します。
- Repeatable Read(MySQL デフォルト)
この分離レベルでは、一つのトランザクションが実行中に同じデータを複数回読み取る場合、同じ結果を得られます。つまり、ノンリピータブルリードを避けられます。ただし、ファントムリードはまだ発生する可能性があります。MySQL は多版型並行制御(MVCC)技術を使ってこの分離レベルを実現します。データの複数バージョンを保存することで、異なるトランザクションが異なるバージョンのデータを見られるようにし、トランザクションの分離性を保証します。
- Serializable(シリアライズ可能)
この分離レベルでは、トランザクション同士は完全に分離されます。まるでトランザクションが順番に実行されるようになります。ダーティリード、ノンリピータブルリード、ファントムリードを避けられます。ただし、この分離レベルはデータベースの並行性能を大きく下げます。トランザクション間の完全な分離を保証するため、厳格なロックが必要になるためです。
トランザクション分離レベルを確認する:
SELECT @@TRANSACTION_ISOLATION;:現在のデータベースのトランザクション分離レベルを確認するために使います。
トランザクション分離レベルを設定する:
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL {READUNCOMMITTED |READCOMMITTED |REPEATABLE READ|SERIALIZABLE };:この文でトランザクション分離レベルを設定できます。SESSIONは現在のセッションだけに有効で、GLOBALはすべての新しい接続セッションに有効です。適切なトランザクション分離レベルは、データ一貫性と並行性能のバランスを考えて選ぶ必要があります。実際のアプリケーションでは、具体的な業務要件と場面に合わせて選択し、性能とデータ一貫性のバランスを取ります。