
RAG
概念
1. RAG とは
RAG = Retrieval(検索) + Generation(生成)
RAG は一つの問題を解決します。大規模モデルは、会社や個人のプライベート知識を知らないという問題です。
方法:まず自分の文書から関連内容を探し、その内容をもとに大規模モデルに回答させます。
2. RAG の動き方
- 質問する → 「会社の年休制度は何ですか?」
- システムが文書から最も関連する数段落を探す
- 質問 + 見つけた段落を一緒に大規模モデルへ渡す → 正確な回答を生成する
基本フロー Demo
Python でローカル RAG を作ります(必要なライブラリは四つだけです)。
txt
pip install langchain langchain-openai langchain-community chromadb「ナレッジベース」(文書の集合)を用意します。例:policy.txt
tex
社員は勤務1年後、5日の有給年休を取得できます。
勤務3年後、年休は10日に増えます。
年休は翌年へ繰り越せません。完全なコード:
python
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# === 1. 自分の文書を読み込む ===
loader = TextLoader("policy.txt", encoding="utf-8")
docs = loader.load()
# === 2. テキストを分割する ===
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(docs)
# === 3. ベクトル化してローカルデータベースへ保存する ===
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(
api_key="あなたのAPI_KEY",
base_url="https://open.bigmodel.cn/api/paas/v4" # 智譜を使う場合
# base_url="https://api.openai.com/v1" # OpenAI を使う場合
)
)
# === 4. retriever を構築する ===
retriever = vectorstore.as_retriever()
# === 5. Prompt テンプレートを構築する ===
template = """あなたは HR アシスタントです。以下のコンテキストに基づいて質問に答えてください:
{context}
質問:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
# === 6. 大規模モデルを呼び出す ===
llm = ChatOpenAI(
model="glm-4.7-flash",
api_key="あなたのAPI_KEY",
base_url="https://open.bigmodel.cn/api/paas/v4"
)
# === 7. RAG chain を組み立てる(LCEL 書き方)===
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# === 8. 質問する ===
answer = rag_chain.invoke("勤務2年の場合、年休は何日ありますか?")
print(answer)原理図
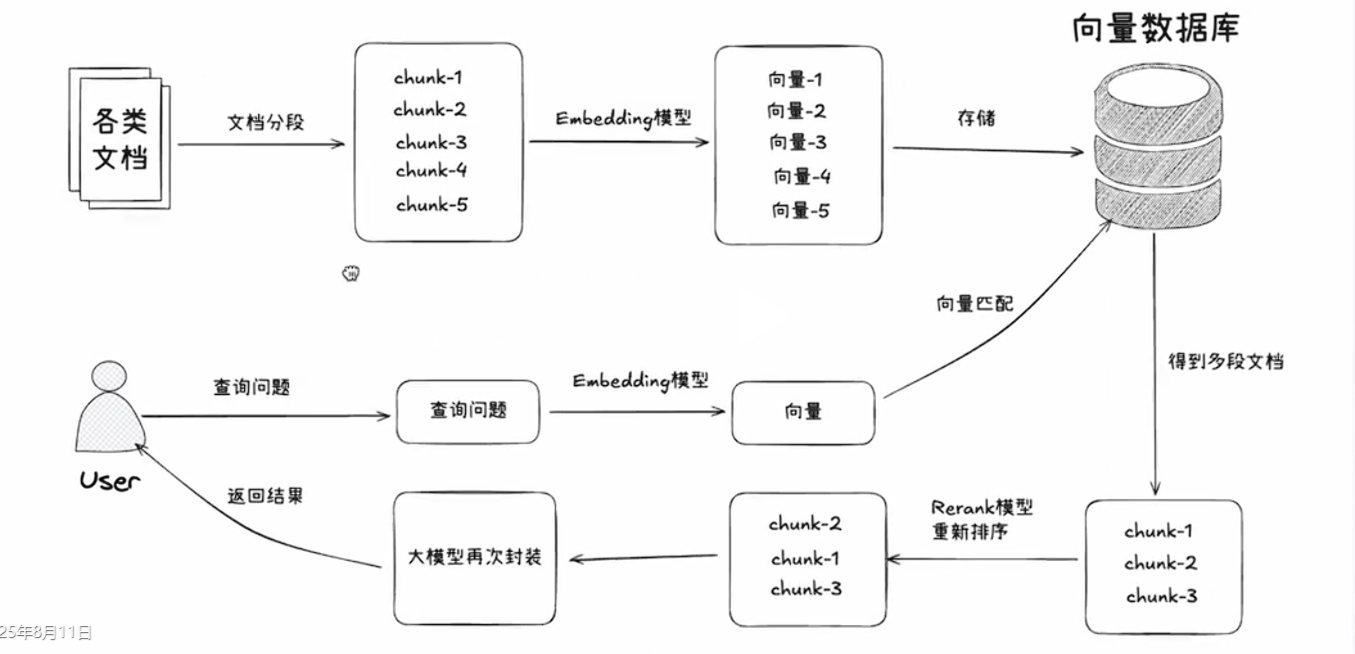
フローをまとめると次の通りです。
- 文書 → チャンク分割 → ベクトル化 → 保存(Chroma はローカルベクトルストア)
- 質問時に、まず関連段落を検索し、その後で大規模モデルへ渡す
- 全体の流れは LangChain の LCEL で一行の chain として接続する