
JavaSE
この記事では、JavaSE の基礎知識を中心に説明します。
導入
まず、基本的な DOS コマンドを確認する。
| コマンド | 意味 |
|---|---|
| dir | 現在のパスを表示する |
| cd | ディレクトリに移動する |
| cd.. | 一つ上の階層に戻る |
| cls | 画面をクリアする |
| javac | Java ファイルをコンパイルする |
| java | class ファイルを実行する |
| exit | DOS ウィンドウを終了する |
| c:/d: | ドライブを切り替える |
最初の Java ファイル
test.java に次のコードを書く。
public class test{
public static void main(String [] args){
System.out.println("Hello World!");
}
}コンソールで次のコマンドを順に実行する。
javac test.java
java test
次の内容が出力される。
Hello World!
これで最初の Java ファイルの実行は完了する。
ここまではテキストエディタで作業した。
以降は IDEA を使ってコードを書き、実行する。
Java のロードと実行
Java プログラムの実行には、重要な段階が二つある。
- コンパイル段階
- 実行段階
コンパイル段階では、Java のソースプログラムが Java の文法に合っているかを確認します。問題がなければ、バイトコードファイルである class ファイルが生成されます。
バイトコードファイルは純粋なバイナリではないため、OS 上で直接実行することはできない。
その後、JDK の javac コマンドでコンパイルする。
public class と class の違い
- 一つの Java ソースファイルには複数の
classを書ける - 一つの Java ソースファイルに
public classは必須ではない - 一つの
classから一つのバイトコードファイルが生成される publicが付いたクラスが存在する場合、クラス名はファイル名と同じでなければならない- 各
classにはmainメソッドを書けるため、それぞれプログラムの入口にできる
データ型
基本概念
役割
- データにはそれぞれ型があり、型によって内部で確保されるメモリサイズが異なる。
- データ型は、プログラム実行時に JVM がどれだけのメモリ領域を確保すべきかを決める。
分類
- 基本データ型
- 参照データ型
基本データ型は、四つの大分類、八つの型に分けられる。
- 整数型
byte short int long - 浮動小数点型
float double - 真偽値型
boolean - 文字型
char
範囲とサイズ
| キーワード | 型の説明 | サイズ | 例 |
|---|---|---|---|
| byte | バイト型 | 1 バイト | (-128~127) |
| short | 短整数型 | 2 バイト | (-32768~32767) |
| int | 整数型 | 4 バイト | 1 |
| long | 長整数型 | 8 バイト | 1L |
| float | 単精度浮動小数点型 | 4 バイト | 0.0f |
| double | 倍精度浮動小数点型 | 8 バイト | 0.00d |
| boolean | 真偽値型 | 2 バイト | true/false |
| char | 文字型 | 1 バイト | '\u0000' |
注:バイト(byte) 1 byte = 8 bit、つまり 1 バイト = 8 ビット
1 ビットは 1 桁の 2 進数を表す
1 KB = 1024 Byte
1 MB = 1024 KB
変換ルール
- 八つの基本データ型のうち、
boolean以外の型は相互に変換できる。 - 小さい容量から大きい容量への変換は自動型変換と呼ばれる。容量の順序は次の通り。
byte short(char) int long float double
注:浮動小数点型は、何バイトであっても整数型より容量が大きい。charとshortは表せる種類の数は同じだが、charはより大きい正の整数を扱える。 - 大きい容量から小さい容量への変換は強制型変換と呼ばれる。強制変換記号が必要で、コンパイルは通るが、実行時に精度が失われる可能性がある。
- リテラルが
byte short charの範囲を超えていなければ、そのまま代入できる。 byte short charの混合演算では、まずint型に変換してから演算する。- 複数のデータ型が混在する演算では、まず容量が最大の型に変換してから演算する。
演算子
算術演算子
| 記号 | 説明 |
|---|---|
| +、-、*、/、% | それぞれ、加算、減算、乗算、除算、剰余 |
| ++ | 1 増やす |
| -- | 1 減らす |
関係演算子
この種類の演算子は二つの値の関係を比較し、true または false を返します。
| 記号 | 説明 |
|---|---|
| == | 左右の値が等しいかを判定する |
| != | 左右の値が等しくないかを判定する |
| > < >= <= | それぞれ、大なり、小なり、以上、以下 |
| += | 加算代入。i += 1 は i = i + 1 と同じ |
論理演算子
| 記号 | 説明 |
|---|---|
| && | 論理 AND。両辺が true の場合のみ結果が true |
| ll | 論理 OR。どちらか一方が true なら結果が true |
| ! | 論理 NOT |
条件演算子
- 三項演算子とも呼ばれる
- 構文:
真偽値式(x) ? 式(a) : 式(b) xがtrueならaを実行し、falseならbを実行する
制御文
分類
| キーワード | 意味 |
|---|---|
| if-else | 条件に応じて異なるコードブロックを実行する |
| switch | 式に応じて異なる分岐を実行する |
| for() | コードを繰り返し実行する。初期値や回数を指定できる |
| while | 条件を満たす間、コードを繰り返し実行する |
| do-while | 先に処理を実行し、その後で条件を判定するループ文 |
| break | switch の実行を終了し、現在のコードブロックから抜ける |
| continue | 今回のループを終了し、次のループに進む |
| return | 現在のメソッドを終了し、呼び出し元へ戻る |
1. if - else
if ("真偽値式"){
//コードブロック1
}else{
//コードブロック2
}if 内の真偽値式が true を返す場合はコードブロック 1 を実行し、そうでなければコードブロック 2 を実行する。else が複数ある場合は次のように書く。
if ("真偽値式1"){
//コードブロック1
}else if("真偽値式2"){
//コードブロック2
}
...
else{
//コードブロック3
}条件の順番に従って判定し、すべて false の場合はコードブロック 3 を実行する。if 文の中に一行しかコードがない場合、波括弧は省略できる。ただし一般的には使わない。
2. switch 文
switch(int または String 型のリテラルや変数){
case 値1:
//値1に一致した場合、このコードブロックを実行する
break;
case 値2:
//値2に一致した場合、このコードブロックを実行する
break;
default:
//すべてのcaseに一致しない場合、このコードブロックを実行する
break;
}
//注意1:switch の式には、整数型またはそのラッパー型、列挙型、文字列型(Java7以降)を使える
//注意2:case ブロックに break がない場合、プログラムは下へ続けて実行される(一致判定は再度行われない)
//この現象を case のフォールスルーという3. for ループ
for (初期条件;ループ条件;ループ制御変数の更新処理){
//ループ本体
}例:
for (int i = 1; i <=5; i++){
System.out.println("i --> " + i);
}上のコードでは、初期値として i = 1 を指定している。
ループ本体はまず変数 i の値 --> 1 を出力する。
ループ本体の実行後、ループ制御変数 i は 1 増える。
その後、更新後の i が 5 以下かどうかを判定する。true ならループ本体を続けて実行する。
この流れから、出力結果は次のように推測できる。
i -->1
i -->2
i -->3
i-->4
i -->5
i -->6
foreach
集合内の要素の値を素早く走査するための、簡潔な構文です。
for (集合要素のデータ型 各走査で現在の要素を表す変数名 : 走査対象の配列または集合){
//ループ本体
}例:
int[] numbers = {1,2,3,4,5};
for(int number : numbers){
System.out.print(number);
}最終的な出力は次の通り。
12345
4. while ループ
while(真偽値式){
//ループ本体
}真偽値式が true の場合、ループ本体のコードブロックが実行される。無限ループを避ける必要がある。do-while ループは次の通り。
do{
//ループ本体
}while(真偽値式);これは先に実行し、その後で判定するループ方式です。
5. 制御文 break & continue
break
break;は完全な文として使える。breakはswitch文でswitch文を終了するために使う。breakはループ文(for、while、do while)でループを終了するために使う。
continue
continue;は完全な文として使える。- 直接次のループに進むことを表す。
6. ジャンプ文
ラベル(label)と break を組み合わせることで、多重ループから抜けられる。
//外側のforに名前を付ける
outerLoop:for (int i = 1; i <= 3; i++) {
System.out.println("Outer loop: " + i);
//内側のforに名前を付ける
innerLoop:for (int j = 1; j <= 3; j++) {
System.out.println("Inner loop: " + j);
if (i == 2 && j == 2) {
break outerLoop; // 条件を満たしたときに外側のループを抜ける
}
}
}上のコードでは、outerLoop の条件を満たした場合、すべてのループが直接終了する。
メソッド
基本概念
メソッドとは、特定の機能を実行するためのコードのまとまりです。再利用できます。
メソッドはクラス本体の中に定義する。メソッド本体の中にさらにメソッドを入れ子で定義することはできない。たとえば、main メソッド内に別のメソッドを定義することはできない。
- メソッドの構造
[修飾子リスト] 戻り値の型 メソッド名 (仮引数リスト) {
メソッド本体;
}構造の説明
戻り値の型は、実行結果のデータ型を決めます。戻り値にはすべての Java 型を使えます。
メソッドに戻り値がない場合は、必ず void と書く。
戻り値が決まっている場合は return が必要です。なければ JVM がエラーを出します。
メソッド名
合法な識別子であればよい。
一般的にはキャメルケースを使う。つまり、最初の単語の先頭文字は小文字、後続の単語の先頭文字は大文字にする。
詳細は Alibaba Java 開発マニュアルを参照する。
仮引数リスト
仮引数はローカル変数です。
仮引数は複数指定でき、カンマで区切る。
このメソッドを呼び出すとき、実際に渡される引数を実引数という。
実引数は仮引数と個数、型、順序がすべて同じでなければならない。
メソッド本体
メソッド本体は波括弧で囲む必要があり、上から下へ順に実行される。
メソッドの呼び出し
staticが付いたメソッドを呼び出すクラス名.メソッド名(実引数)の形式で呼び出す。staticが付いていないメソッドを呼び出す
先にオブジェクトを作成し、オブジェクト名.メソッド名(実引数)の形式で呼び出す。- メソッドが自分自身を呼び出す(メソッド再帰)
使用頻度は低く、スタックメモリがオーバーフローするリスクもあるため、ここでは説明しない。
メソッドのオーバーロード(Overload)
同じクラス内で機能が似ている二つのメソッドについて、できるだけ名前を一致させ、仮引数リストだけを異ならせる。
メソッドのオーバーロードは戻り値の型や修飾子リストとは関係がなく、メソッド名と仮引数リストだけに関係する。
例:
//メソッドのオーバーロード
public class Overload {
public static void main(String [] args){
System.out.println(sum(1,2));
System.out.println(sum(1.0,2.0)); //この時点では、実引数のデータ型で区別される。
System.out.println(sum(1L,2L));
}
public static int sum(int a , int b){
return a + b;
}
public static long sum(long a , long b){
return a + b;
}
public static double sum(double a , double b){
return a + b;
}
}メソッドの三大特性
Java の三大特性は、Java で最も基礎的で重要な概念です。
それぞれ次の通り。
- カプセル化
カプセル化は、データとメソッドをクラス内部に隠し、外部には公開されたアクセス方法だけを出す仕組みです。これによりデータの完全性と安全性を守り、コードをよりモジュール化できます。 - 継承
継承により、あるクラス(子クラス)は別のクラス(親クラス)の属性とメソッドを引き継げる。これはコードの再利用と拡張に役立ち、ソフトウェア開発の効率を高める。 - ポリモーフィズム
ポリモーフィズムとは、異なるオブジェクトが同じメッセージに対して異なる応答をすることを指す。親クラス型の参照で子クラスオブジェクトを指し、実際のオブジェクト型に応じて対応するメソッドを呼び出せる。これによりコードの柔軟性と拡張性が高まる。
カプセル化
private メンバ変数:クラスのメンバ変数を private に設定し、これらの変数がクラス内部からのみアクセス、変更できるようにする。外部コードは private 変数に直接アクセスしたり変更したりできないため、データの安全性と完全性が保証される。
public メソッド:private メンバ変数は外部から直接アクセスできません。しかし、クラス内に public メソッドを定義すれば、これらの private 変数へのアクセスと変更ができます。通常は getter メソッドと setter メソッドを含みます。この方式では、外部コードは内部実装の詳細を知らなくても、public メソッドを呼び出して private 変数の値に間接的にアクセス、変更できます。
コード例(User を例にする):
public class User{
private String name;
private int age;
private String sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}継承
継承はオブジェクト指向プログラミング(OOP)の基本特性の一つです。既存のクラスをもとに新しいクラスを作成できる仕組みです。コードの再利用に役立ち、開発効率を高めます。Java では、継承は extends キーワードで実現します。
1. 基本概念
- 親クラスと子クラス:継承されるクラスを親クラス(基底クラス、スーパークラス)と呼び、継承するクラスを子クラス(派生クラス)と呼ぶ。子クラスは親クラスの属性とメソッドを継承できる。
- コード再利用:継承により、子クラスは親クラスのコードを再利用できるため、同じコードの重複記述を避けられる。これにより冗長性が減り、保守性が向上する。
- 機能拡張:子クラスは親クラスを継承したうえで、新しい属性やメソッドを追加できる。これにより、より具体的な要求を満たせる。
2. Java における継承の実装
子クラスの定義で extends キーワードを使い、継承する親クラスを指定する。
例:
public class Animal {
private String name;
//コンストラクタ
public Animal(String name) {
this.name = name;
}
public void eat() {
System.out.println(name + " is eating.");
}
}
public class Dog extends Animal {
public Dog(String name) {
super(name); // 親クラスのコンストラクタを呼び出す
}
public void bark() {
System.out.println(name + " is barking.");
}
}この例では、Dog クラスが Animal クラスを継承している。継承によって、Dog クラスは Animal クラスの name 属性と eat メソッドを取得する。
同時に、Dog クラスは新しい bark メソッドも追加している。
3. 親クラスのメンバへのアクセス
継承されたメンバ:子クラスは親クラスの非 private メンバにアクセスできる。super キーワード:子クラスは super キーワードを使って親クラスのメンバを参照できる。
4. メソッドのオーバーライド(Overriding)
概念:子クラスは、親クラスと同じメソッド名、引数リスト、戻り値型を持つメソッドを書くことで、親クラスのメソッド実装を上書きできます。これをメソッドのオーバーライドといいます。@Override アノテーションを使うと、そのメソッドが親クラスのメソッドをオーバーライドしていることを明示できます。
5. 継承の階層構造
多段継承:あるクラスは、すでに別のクラスを継承しているクラスをさらに継承できる。これにより多段の継承階層が形成される。
インターフェースと継承:クラス間の継承だけでなく、Java はインターフェースとクラスの継承関係もサポートする。これによりオブジェクト指向プログラミングの柔軟性が高まる。
6. 継承のメリットとデメリット
メリット:コード再利用、拡張性が高い、保守しやすい。
デメリット:クラス間の結合度が高くなり、システムの複雑性が増す可能性がある。継承階層が多すぎると性能低下につながる場合もある。
ポリモーフィズム
まず、ポリモーフィズムを使わない例を見る。
class Master {
public void feed(Dog d){
d.eat();
}
}
class Dog {
public void eat(){
System.out.println("小黑在啃骨头");
}
}
public class Test {
public static void main(String[]args){
Master wu = new Master();
Dog xiaohei = new Dog();
wu.feed(xiaohei);
}
}上の例でペットを追加する場合、新しいクラスを追加するだけでなく、Master のコードも変更する必要がある。
したがって、Master クラスの拡張性は弱いと言える。
ポリモーフィズムの仕組みを使い、pet というペットクラスを作成し、すべてのペットがこのクラスを継承するようにする。
そして、主人クラスにはペットクラスを餌付けさせる。
class Master {
public void feed(Pet p){
p.eat();
}
}
class Pet {
public void eat(){
System.out.println("请重写此方法");
}
}
class Dog extends Pet{
public void eat(){
System.out.println("小黑在啃骨头");
}
}
public class Test {
public static void main(String[]args){
Master wu = new Master();
Dog xiaohei = new Dog();
wu.feed(xiaohei);
}
}このようにすれば、新しいペットを追加するときは、そのペットにペットクラスを継承させるだけでよく、Master クラスを変更する必要がない。
これにより Master クラスの拡張性が高まる。
補足
アップキャスト(upcasting)
子クラスを親型に変換することを自動型変換という。
ダウンキャスト(downcasting)
親クラスを子型に変換することを強制型変換といいます。強制変換記号が必要です。
instanceof
使い方:
形式:参照 instanceof データ型名。例:a instanceof Animal
演算結果のデータ型は真偽値型です。
true は、a が指しているオブジェクトが Animal 型であることを表します。false は、a が指しているオブジェクトが Animal 型ではないことを表します。
Java の規約では、強制型変換の前に instanceof 演算子で判定し、例外を避けることが求められる。
重要キーワード
this
this の構文は this. と this() です。this は静的メソッド内には現れない。this は多くの場合省略できる。
ローカル変数とインスタンス変数を区別するときは省略できない。setter メソッドを考えるとよい。this() はコンストラクタの最初の行にしか書けず、同じクラス内の対応するコンストラクタを呼び出すために使う。
super
super の構文は super. と super() です。super は静的メソッド内には現れない。super は多くの場合省略できる。super() は親クラスのコンストラクタを呼び出すために使う。
final
final は修飾子です。次の規則があります。
- 修飾されたクラスは継承できない。
- 修飾されたメソッドはオーバーライドできない。
- 修飾された変数は一度しか代入できない。
- 修飾されたインスタンス変数は手動で代入しなければならない。
- 修飾された参照は、一度オブジェクトを指すと変更できない。
staticと一緒に修飾された変数は 定数 と呼ばれる。
public static final double PI = 3.1415926;
//定数名はすべて大文字にするstatic
staticはメソッドを修飾するために使う。修飾されたメソッドはクラス名.メソッド名の形式でアクセスできる。staticは変数も修飾できる。これは静的変数と呼ばれ、クラスロード時に初期化が完了し、メソッド領域メモリに保存される。- 静的コードブロック も定義できる。
static{
java文;
}静的コードブロックはクラスロード時に実行され、一度だけ実行される。
用途には、接続プールの初期化、XML 設定ファイルの解析などがある。
package & import
パッケージ化はプログラムの管理をしやすくする。
プログラムの最初の行に一文だけ書ける。
パッケージ名の命名規則:
会社ドメインの逆順 + プロジェクト名 + モジュール名 + 機能すべて小文字にし、. で区切る
インポートの構文:
improt クラス名;
imptot パッケージ名.クラス名;注意:java.lang.* は Java のコアクラスなので手動でインポートする必要はない。
IDEA を使うと、パッケージ化とインポートは自動で行われる。
抽象クラスとインターフェース
抽象クラス(使用頻度は低い)
概念
- クラス同士に共通の特徴がある場合、それを抽出したものが抽象クラスです。
たとえば猫と犬はどちらもペットです。共通点を抽出して、ペットという抽象クラスにできます。 - クラス自体は実体として存在しないため、抽象クラスはオブジェクトを作成できない。つまりインスタンス化できない。
- ただし抽象クラスは自分自身のコンストラクタを持つ。
- したがって抽象クラスは子クラスに継承されるためだけに存在し、子クラスはインスタンス化できる。
- 抽象クラスは
finalで修飾できない。finalで修飾されたクラスは継承できないためです。
構文:
[修飾子リスト] abstract class クラス名{クラス本体}抽象メソッド(メソッド本体のないメソッド / 未実装メソッド)
構文:
public abstract void doSome();抽象クラス内の抽象メソッドは、子クラスに継承された場合、必ずオーバーライドしなければならない。
インターフェース
完全に抽象的な抽象クラスは、特殊な抽象クラスとみなせる。これを インターフェース と呼ぶ。
インターフェースは新しい定義方法を使う。
[修飾子リスト] interface インターフェース名{}特徴
- インターフェースは複数のインターフェースを継承できる。
interface C extends A,B{}- インターフェース内には
定数と抽象メソッドだけを書ける。 - インターフェース内のメソッドはすべて public かつ abstract なので、定義時に
public abstractを省略できる。 - インターフェース内のすべての変数は定数なので、次のように簡略化できる。
public static final double PI = 3.1415926;
double PI=3.1415926;役割:ポリモーフィズムと似ており、インターフェース指向プログラミングによって疎結合で拡張しやすい設計にする。
抽象クラスとの違い
- インターフェースは完全抽象、抽象クラスは半抽象です。
- インターフェースにはコンストラクタがなく、抽象クラスにはコンストラクタがある。
- インターフェースは多重継承をサポートしますが、クラス同士は単一継承のみです。
- 一つのクラスは複数のインターフェースを実装できるが、抽象クラスは一つの抽象クラスだけを継承できる。
- インターフェースには定数と抽象メソッドだけがある。
インターフェースの実装
クラス同士の関係は継承と呼ぶ。
クラスとインターフェースの関係は実装と呼び、impements を使う。
構文:
interface MyMath{}
class MyMathImpl implements MyMath{}インターフェースもポリモーフィズムと組み合わせて使える。
MyMath mm = new MyMathImpl();クラスは同時に複数のインターフェースを実装できる。
interface A{}
interface B{}
interface C{}
class D implements A,B,C{}
A a = new D();
B b = new D();
C c = new D();一つのクラスは別のクラスを継承しながら、インターフェースを実装できる。
注意:
extendsが先で、implementsが後です。
class A extends B implements C{}AObject クラス
概念
Object は Java のすべてのクラスのルートクラスであり、直接または間接的な親クラスです。
したがって、作成した任意のクラスが継承するクラスを明示していない場合、デフォルトで Object を継承する。
Object には基本的なメソッドが定義されており、これらのメソッドはすべてのオブジェクトで使用できる。
1. boolean equals(Object obj)
ソースコードは次の通り。
public boolean equals(Object obj) {
//Object では == を使って二つのオブジェクトを直接比較する
return (this == obj);
}Object は、以後すべてのクラスでこのメソッドをオーバーライドすることを推奨している。String クラスはこのメソッドをオーバーライドしている。
public final class String{
public boolean equals(Object anObject) {
// まず二つのオブジェクトが指すメモリアドレスを直接比較する
if (this == anObject) {
//メモリアドレスが同じなら true を返す
return true;
}
// 次に、渡された anObject が String 型のインスタンスかどうかを比較する
if (anObject instanceof String) {
// そうであれば String 型に強制変換する
String anotherString = (String)anObject;
// 変換後の文字列の長さを取得する
int n = value.length;
if (n == anotherString.value.length) {
//長さが同じ場合
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//文字ごとに比較する
while (n-- != 0) {
if (v1[i] != v2[i])
//異なる文字があれば false を返す
return false;
i++;
}
// ここまで来たら長さが同じで、各文字も一致している
return true;
}
//ここまで来たら文字列の長さが一致しない
}
//ここまで来たら型が String 型ではない
return false;
}
}2. String toString()
ソースコードは次の通り。
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}Object の toString() メソッドも非常に基本的です。getClass().getName() によって取得した実行時クラス名と、Integer.toHexString(hashCode()) によって取得したオブジェクトのハッシュコードの 16 進表現だけを返します。
このメソッドも、わかりやすい情報を返すように変更することが推奨される。
オーバーライド例:
public class Dog {
//name と age という二つの属性を持つペット犬クラスを定義する
private String name;
private int age;
//toString() をオーバーライドし、犬の name と age を返す
@Override
public String toString() {
return "Dog{name='" + name + "', age=" + age + '}';
}
}3. Class<?> getClass()
Object クラスの getClass() メソッドは、オブジェクトの実行時クラスの Class オブジェクトを取得するために使う。
このメソッドは、そのオブジェクトが実際に属するクラスを表す Class インスタンスを返す。
メソッドの宣言は次の通り。
//`final` で修飾されており、オーバーライドできないことを意味する
public final Class<?> getClass()4. hashCode()
オブジェクトのハッシュコード値を返す。
このメソッドのデフォルト実装はネイティブメソッド(native method)です。JVM のネイティブコードで実装されています。
配列
概念
- 配列は参照データ型であり、親クラスは
Objectです。 - 配列は複数の要素を格納できます。配列はデータの集合です。
- 配列は
基本データ型と参照データ型を格納できる。 - 配列は参照型なので、ヒープメモリに格納される。
- 配列は Java オブジェクトを直接格納できないが、その
参照(メモリアドレス)は格納できる。
分類
- 一次元配列
- 二次元配列
- 多次元配列
二次元配列は、各要素が一次元配列になっている構造です。
特徴
- すべての配列には
length属性があり、配列内の要素数を取得するために使う。 - 配列内の要素は型を統一する必要がある。
- 配列内の要素のメモリアドレスは連続している。
- 配列は単純なデータ構造です。
- 先頭要素のメモリアドレスが、配列オブジェクト全体のメモリアドレスとして扱われる。
- 配列内の各要素には添字があり、添字は 0 から始まり 1 ずつ増える。最後の要素の添字は
length - 1です。 - 配列内の要素の保存や取得は、添字を通じて行う。
メリット
添字による検索効率が非常に高い。最も検索効率が高いデータ構造と言える。
理由は、メモリアドレスが連続しており、要素のデータ型と占有サイズも同じなので、オフセット から直接計算できるためです。
数学的な式で要素のメモリアドレスを計算できるため、10 個の要素でも 1 万個の要素でも検索効率は同じです。
デメリット
- 配列要素のアドレス連続性を保証するため、ランダムな追加や削除では、後ろの要素を一斉に前または後ろへ移動する必要がある。
- 大量のデータを格納できない。メモリ上に大きく連続した領域を見つけるのが難しいためです。
注意:最後の要素に対する追加や削除の効率には影響しない。
補足
配列の拡容
配列は一度確定すると長さを変更できない。
元の配列がいっぱいになった場合、より大きい新しい配列を作成し、元の配列内の要素を新しい配列にコピーする。
そのため配列コピーの効率は低い。できるだけ配列の拡容を発生させない。
System.arraycopy のソース:
//第一引数は元配列、第二引数は開始位置、第三引数は対象配列、第四引数は対象配列の位置、第五引数はコピー長
public static native void arraycopy(Object src,int srcPos,Object dest,int destPos,int length);初期化
int 型配列を例にする。
- 静的初期化
int[] array = {100,2100,513,12};- 動的初期化
//ここでの 5 は配列内の要素数を表す
//初期状態の五つの要素はすべて int 型のデフォルト値 0
int[] array = new int[5];アクセス時は 配列オブジェクト[添字] の形式を使う。たとえば array[1] は添字 1 の要素にアクセスすることを表す。
配列の走査(for ループを使う):
for(int i = 0; i < array.length; i++){
System.out.println(a[i]);
}
//同じ方式で逆順走査も実現できるまた、ポリモーフィズムと組み合わせて使える。
Animal Cat Birdの三つのクラスCatとBirdはAnimalを継承する
Animal 配列を作成し、その子クラスを格納できる。
Animal[] animals = {new Cat(),new Bird()};
子クラス特有のメソッドを走査時に使いたい場合は、for ループ内で instanceof 判定を追加する。
if(animals[i] instanceof Cat){
Cat cat = (Cat)animals[i];
}二次元配列
二次元配列は特殊な一次元配列として理解できます。各要素が一次元配列です。
初期化
//静的初期化
int[][] array1 = {{1,2,3},{4,5,1}};
//動的初期化
int[][] array2 = new int[3][4];
//三行四列の二次元配列を作成するという意味二次元配列の走査
同じく for ループを使う。ただし配列の内側にも一次元配列があるため、二つの for ループを入れ子にして走査する。
public class test{
public static void main(String[] args) {
int[][] array = {{1,2,3},{4,5,6},{7,8,9}};
for(int i =0;i<array.length;i++){
for(int j = 0;j < array[i].length;j++){
System.out.print(array[i][j]);
}
System.out.println();
}
}
}例外
概念
- プログラム実行中に発生する異常な状況を
例外と呼ぶ。 - Java は例外処理方式を提供している。Java はその例外情報をコンソールに出力し、プログラマが参考にできるようにする。
- プログラマは例外情報を見て、プログラムを修正できる。
- Java における例外はすべて
クラスの形で存在する。 - 各例外クラスはオブジェクトを作成できる。
例:
int a = 10;
int b = 0;
int c =a / b ;
//JVM がここまで実行すると、例外オブジェクトを new する:
//ArithmeticException("/ by zero")
//そしてオブジェクトを投げ、コンソールに出力する。例外の分類
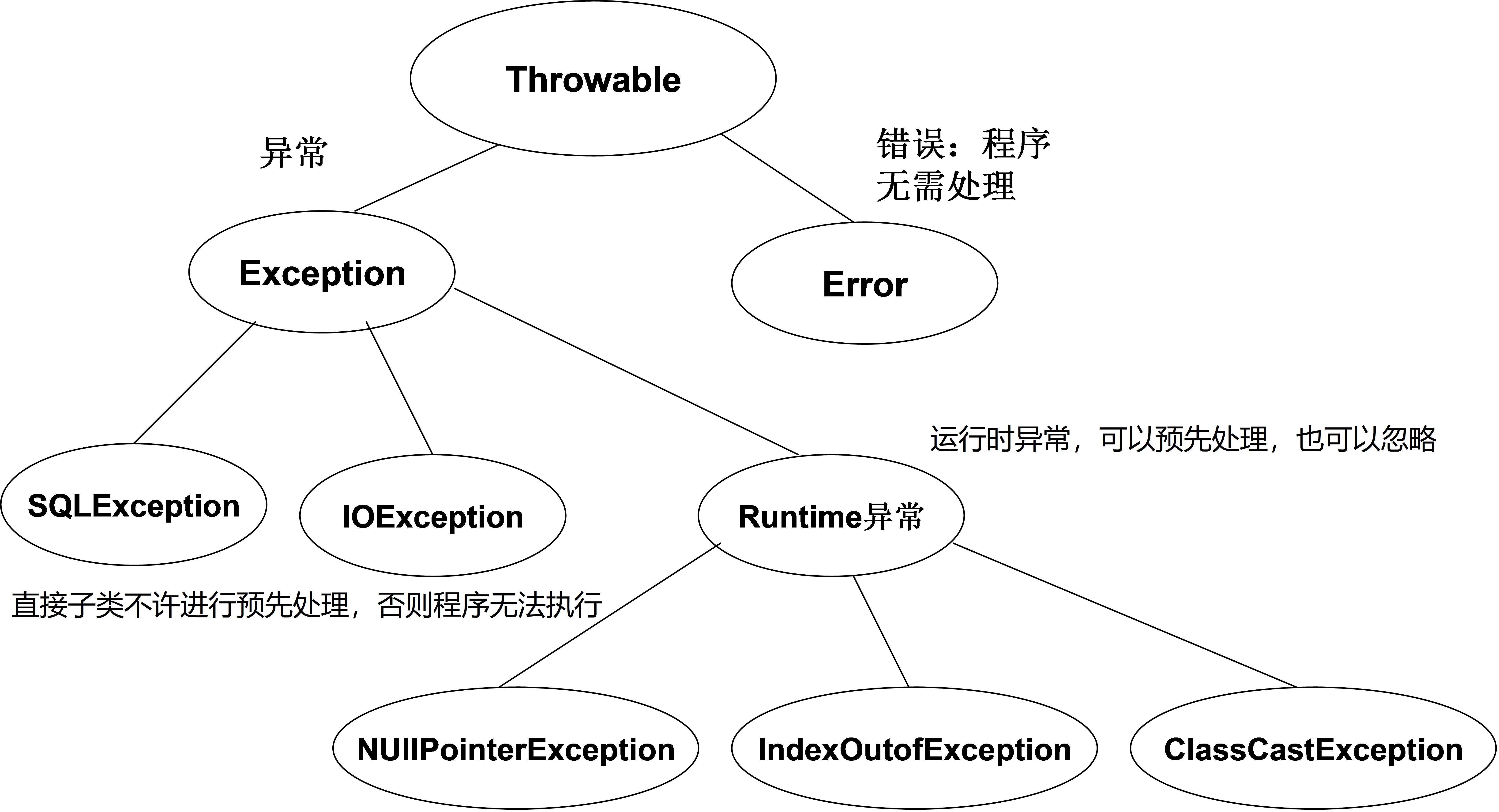
RuntimeException は発生しにくく、事前処理は不要です。ExceptionSubClass は発生しやすく、実行前に事前処理が必要です。
四つのよくある例外:
NullPointerException(Null ポインタ例外)ClassCastException(型変換例外)IndexOutOfBoundsException(配列添字範囲外例外)NumberFormatException(数値フォーマット例外)
//数字を入力すべきなので、数値フォーマット例外が発生する
Inteager a = new Integer(s:"中文");Java の例外処理方式
- メソッド宣言の位置で
throwsキーワードを使い、例外を上に投げる。 try catch文を使って例外を捕捉する。
構文:
try {
//例外が発生する可能性のあるコード
} catch(Exception e) {
//例外処理
}注意:
- 例外を上に投げる方式を採用した場合、このメソッド内で例外が発生した位置より後ろのコードは実行されない。
try文ブロック内で例外が発生した行より後ろのコードも実行されない。catchは複数書ける。上から下へ、範囲は小さいものから大きいものへ書く。catchの後ろでは|記号で例外型をつなげることもできる。
finally 句
特徴:
try catch文の後に使う。- 句内のコードは必ず実行される。
try内で例外が発生しても実行される。 try内にreturn;文があっても、句内のコードは実行される。finally句には通常、リソースの解放やクローズ処理を書く。try内に仮想マシンを終了する命令System.exit(status: 0);がある場合、finallyは実行されない。
構文
try{
}catch(){
}finally{
}カスタム例外
SUN が提供する例外だけでは足りない場合があります。以後、業務上発生する例外は自分で定義する必要があります。
定義方式:
手順一:
ExceptionまたはRuntimeExceptionを継承するクラスを書く
手順二:二つのコンストラクタを提供する。一つは引数なしコンストラクタ、一つはString引数付きコンストラクタ
以下はカスタム例外を実際に使う例です。
まず、簡単なカスタム例外クラス CustomException を定義する。
public class CustomException extends Exception {
public CustomException(String message) {
super(message);
}
}次に、簡単な Calculator クラスを用意する。この中には divide メソッドがあり、除数が 0 の場合に CustomException を投げる。
public class Calculator {
public int divide(int numerator, int denominator) throws CustomException {
if (denominator == 0) {
throw new CustomException("除数不能为0");
}
return numerator / denominator;
}
}最後に、main メソッドで Calculator の divide メソッドを呼び出し、発生する可能性のある CustomException 例外を処理する。
public class Main {
public static void main(String[] args) {
Calculator calculator = new Calculator();
try {
int result = calculator.divide(10, 0);
System.out.println("结果是: " + result);
} catch (CustomException e) {
System.err.println("捕获到自定义异常: " + e.getMessage());
}
}
}この例では、10 を 0 で割ろうとすると、Calculator クラスの divide メソッドが CustomException を投げる。main メソッド内の try-catch ブロックがこの例外を捕捉し、例外情報を出力する。
コレクション
コレクションはコンテナであり、他の型のデータを格納できます。前に説明した配列も一種のコレクションです。
すべてのコレクション関連のクラスとインターフェースは java.util パッケージ下にある。
特徴
- コレクションは基本データ型を直接格納できない。ただしコード上では自動ボクシングがあるため意識しなくてよい。
- また、コレクションは Java オブジェクト自体を直接格納するのではなく、その
メモリアドレス、つまり参照を格納する。 - 異なるコレクションは、内部で異なるデータ構造に対応している。
- データ構造とはデータの保存構造のことです。よくある構造には
配列、二分木、連結リスト、ハッシュテーブルなどがあります。
分類
Java のコレクションは二種類に分けられる。
一つは単一要素として保存する方式:java.util.Collection
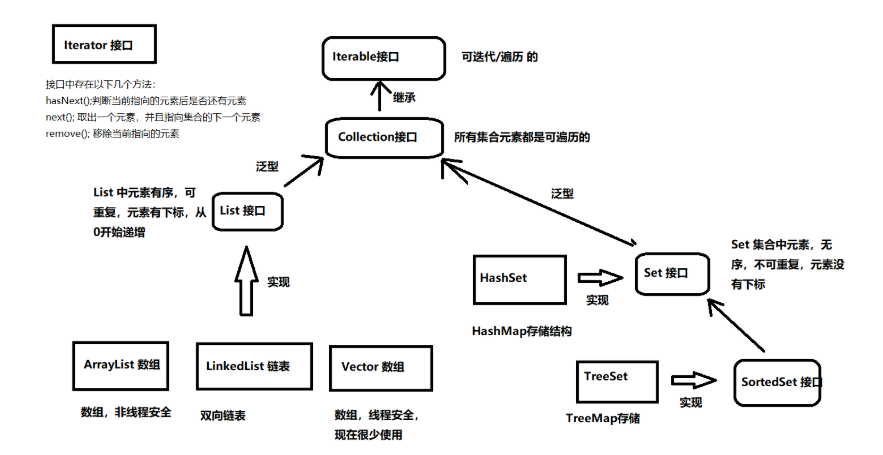
もう一つは キーと値のペア として保存する方式:java.util.Map
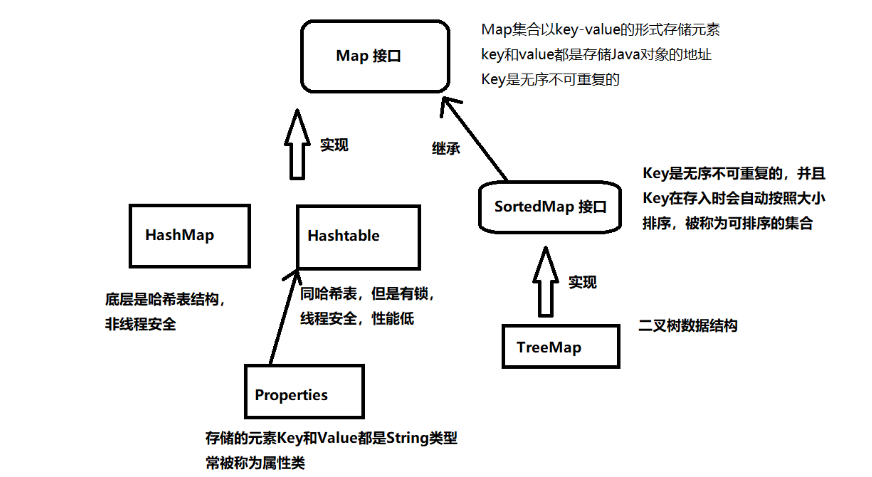
図には各コレクションの特徴が示されている。
よく使うコレクションのまとめ
| コレクション | 保存構造 |
|---|---|
| ArrayList | 配列 |
| LinkedList | 双方向連結リスト |
| HashSet | 内部は HashMap。保存される要素は HashMap の key に相当する |
| TreeSet | 内部は TreeMap。保存される要素は TreeMap の key に相当する |
| HashMap | ハッシュテーブル |
| Properties | スレッドセーフ。key と value は String 型のみ格納可能。設定クラスとしてよく使われる |
| TreeMap | 二分木。key は自動的に大小順でソートされる |
Collection
Collection コレクションに ジェネリクス がない場合、Object のすべての子クラスを格納できる。
ただし ジェネリクス がある場合は、ジェネリクスで指定された型だけを格納できる。
注意:基本データ型とオブジェクト本体は格納できず、ラッパークラスまたはオブジェクトのメモリアドレスだけを格納できる。
よく使うメソッド
| よく使うメソッド | 説明 |
|---|---|
| boolean add(E e) | コレクションに要素を一つ追加する。成功すれば true を返す |
| boolean remove(Object o) | 要素を削除する。内部では equals メソッドを呼び出して比較し、成功すれば true を返す |
| int size() | コレクション内の要素数を返す |
| boolean contains(Object o) | コレクションにその要素が含まれるかを判定する。内部で equals() を呼び出し、含まれていれば true を返す |
| boolean isEmpty() | コレクションが空かどうかを判定する。空なら true を返す |
| void clear() | コレクションを空にする |
| Object[] toArray() | コレクションを配列に変換する |
デモ:
public class Test{
public static void main(String[] args){
//ポリモーフィズム。親型の参照が子型オブジェクトを指す
Collection c = new ArrayList();
//コレクションに要素 1 を追加する
/*注意:Java には自動ボクシング機構があり、実際には次のようになる:
Integer i = new Integer(1);
*/
c.add(1);
//現在のコレクションの要素数を取得する。現在は 1
int size = c.size();
//現在のコレクションに 1 が含まれるか判定する。結果は true
boolean isContains = c.contains(1);
//コレクションを空にする
c.clear();
//コレクションが空か判定する。結果は true
boolean isEmpty = c.isEmpty();
}
}Iterator イテレータ
Collection コレクションだけがイテレータで反復処理できる。Map コレクションでは使えない。
| よく使うメソッド | 説明 |
|---|---|
| boolean hasNext() | 現在指している要素の後ろに要素が存在するかを判定する |
| E next() | 現在指している要素を返し、次の要素を指す |
| remove() | イテレータが現在指している要素を削除する |
使用方法:
main(){
//まず Collection のコレクションを用意する
Collection collections = new ArrayList();
collections.add("元素1");
...
collections.add("元素n");
//イテレータオブジェクトを取得する。このメソッドは Iterator インターフェースから継承される
Iterator<String> it = collections.iterator();
//現在の要素の後ろに要素があるかを判定する
while (iterator.hasNext()) {
//その要素を変数で受け取り、次の要素を指す
String element = iterator.next();
//受け取った要素を出力する
System.out.println(element);
}
}注意:反復処理中にコレクション内の要素を削除する場合は、イテレータの remove メソッドを使う。Collection のメソッドを直接使う場合、新しいイテレータを再取得する必要がある。
List の子クラス
List は Collection の子クラスとして、独自のメソッドを持つ。
これらのメソッドは、このコレクションの特徴に基づいている。
| メソッド | 説明 |
|---|---|
| void add(int index, E element) | 指定した添字に要素を追加する |
| E get(int index) | 指定した添字の要素を取得する |
| E set(int index, E elemtnt) | 指定した添字の要素を変更する |
| int indexOf(Object o) | リスト内で指定要素が最初に現れるインデックスを返す。なければ -1 を返す |
| int lastIndexOf(Object o) | リスト内で指定要素が最後に現れるインデックスを返す。なければ -1 を返す |
| E remove(int index) | 指定したインデックスの要素を削除する |
ArrayList
特徴:
ArrayListはスレッドセーフではない- デフォルトの初期容量は 10
- 内部では最初に長さ 0 の配列を作成し、最初の要素を追加すると長さが 10 になる
- コレクションの内部は
Object配列です
コンストラクタ:
new ArrayList();//デフォルト初期化方式
new ArrayList(20);//初期サイズを指定する
new ArrayList(一个集合);
//たとえば HashSet を ArrayList に変換する配列の拡容:
- 元の容量の 1.5 倍に増える
面接問題:ArrayList のメリットとデメリット
ArrayListは最もよく使われ、配列と同じ特徴を持つ- 配列は検索効率が高い。頻繁に検索する場合に使われる
理由は、各要素の占有サイズが同じで、メモリアドレスが連続しているためです。先頭要素のアドレスが分かっていれば、オフセットから対象要素のメモリアドレスを計算できます。
デメリット:
- 配列は大量のデータを保存できない
- ランダムな要素追加、削除の効率が低い
- 末尾の追加、削除は影響を受けない
LinkedList
特徴:
- 内部は双方向連結リストに保存される
- 三つの部分で構成される:
前のノードのメモリアドレス、データ、次のノードのメモリアドレス - 初期容量はなく、
firstとlastはどちらもnull
Vector(使用頻度は低い。理解しておけばよい)
- 内部は配列
- 初期容量は 10
- 拡容後は元容量の 2 倍。10-20-40-80
Vectorはすべてスレッド同期、スレッドセーフです。synchronizedキーワードが付いているため、使用頻度は低い
Map
Collection とは関係がない。
保存方式は key-value 形式です。key と value はどちらも参照データ型です。
オブジェクトを直接保存するのではなく、オブジェクトのメモリアドレスだけを保存する。
Set コレクション内の要素は、Map コレクションの Key に相当する。
よく使うメソッド
| メソッド | 説明 |
|---|---|
| V put(K key, V value) | コレクションにキーと値のペアを追加する |
| V get(Object key) | key によって value を取得する |
| V remove(Object key) | key によって value を削除する |
| Collection< V> values() | すべての value を取得する |
| Set< K> keySet() | Map コレクション内のすべての key を返す |
走査方式
方式一:すべての key を先に取得し、key によって value を取得する。
Iterator<Integer> it = keys.interator();
while(it.hasNext()){
//key を一つ取り出す
Integer key = it.next();
//key によって value を取得する
String value = map.get(key);
System.out.println(key+"+"+value);
}方式二:Map コレクションを Set コレクションに変換する。
効率が高く、大量データに適している。
Set<Map.Entry<Integer,String>> set = map.entrySet();
Iterator<Map.Entry<Integer,String>> it2 = map.entrySet();
while(it.hasNext()){
Map.Entry<Integer,String> node = it2.next();
Integer key = node.getKey();
String value = node.getValue();
System.out.println(key+"="+value);
}HashMap
特徴:
- コレクションのデフォルト初期容量は 16、デフォルトロードファクタは 0.75
- 初期容量は 2 の倍数でなければならない
- 拡容は元の 2 倍
- デフォルトロードファクタは、HashMap コレクションの容量が 75% に達したとき配列の拡容を開始することを表す
- スレッドセーフではない
HashMap のソースコードには次の属性がある。
final int hash; //実際には key の hashCode()
final K key
V value
Node < K,V> next;HashMap コレクションは key 値として null を許可する。
ただし HashMap コレクションの null key は一つだけです。
理解しておく内容:
hashcode(); が固定値を返す場合、hashMap は単方向リストになる。
この状況をハッシュ分布の偏りという。hashcode() がすべて異なる場合、hashMap は一次元配列になる。
これもハッシュ分布の偏りです。
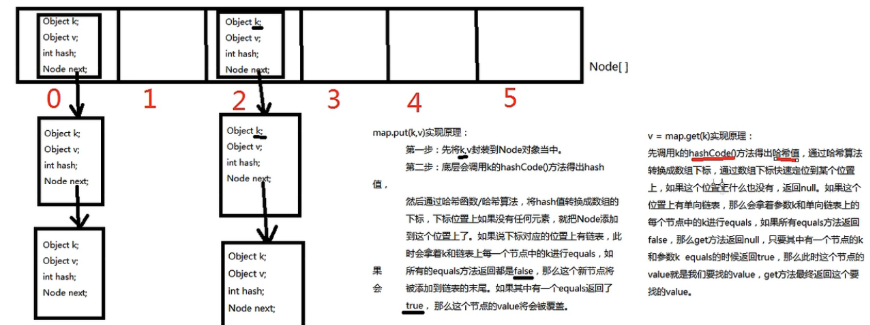
均一なハッシュ分布にするには、hascode(); をオーバーライドする必要があり、一定のコツがある。
【最終結論】HashMap の key 部分に置く要素と HashSet の要素は、equals(); と hashcode(); を同時にオーバーライドする必要がある。
Properties
特徴:
Hashtableを継承している- 初期容量は 11、デフォルトロードファクタは 0.75
- 拡容は元容量の 2 倍に 1 を加える
- スレッドセーフ
- key と value はどちらも文字列であり、空にできない
| よく使うメソッド | 説明 |
|---|---|
| String getProperty(String key) | キーに基づいて属性を取得する |
| Object setProperty(String key, String value) | Hashtable の put メソッドを呼び出す |
TreeMap
特徴:
- 内部は二分木
- 順序なし、重複不可。保存された値は自動的に大小順でソートされる。
Stringは辞書昇順、Integerは数値昇順 - カスタムクラスをソートする場合、比較ルールを宣言する必要がある。
java.lang.Comparable比較インターフェースを実装していない場合、JVM はエラーを出す
アノテーション Annotation
概念
アノテーション:Annotation は参照データ型の一種です。コンパイル後に .Class ファイルが生成されます。
Java が提供するメタデータ機構であり、開発者がコードに追加情報やマークを付けられます。
役割
これらの情報はプログラムの実行ロジックに直接影響しないが、コンパイラ、ツール、実行時環境によって読み取られ、利用される。形式
アノテーションは@記号で始まり、その後にアノテーション名と任意の引数が続く。
例:@SuppressWarnings(value="unchecked")使用場面
package、class、method、fieldなどに付けられる。
Java 組み込みアノテーション
| アノテーション | 説明 |
|---|---|
| @Override | 親クラスのメソッドをオーバーライドする |
| @Deprecated | すでに古く、使用を推奨しない |
| @SuppressWarning("value") | 警告を抑制する。all はすべて、unchecked は未検査を表す |
メタアノテーション
役割:メタアノテーションは他のアノテーションを説明する。
Java では 4 種類の標準 meta-annotation 型が java.lang.annotation 下に定義されている。
| メタアノテーション | 説明 |
|---|---|
| @Target | アノテーションの使用範囲を宣言する |
| @Retention | 通常は Runtime と書き、実行時に有効であることを表します |
| @Document | このアノテーションが javadoc に含まれる |
| @Inherited | 子クラスが親クラスのこのアノテーションを継承できる |
カスタムアノテーション
基本形式:
[修飾子リスト] @interface アノテーション型名{
//アノテーションの引数
String name1();
//デフォルト値付きの引数
String name2() default "默认值";
}アノテーションに引数を追加する必要がある場合、カスタムアノテーション本体内でアノテーション引数を宣言する。
形式は 引数型 + 引数名 + (); です。
注意:アノテーション内の属性が一つだけの場合、名前は
valueにすることが推奨される。
マルチスレッド
スレッドとプロセス
- プロセス:一つのアプリケーションは一つのプロセスです。たとえば 360 セキュリティソフト本体は一つのプロセスです。
- スレッド:一つのプロセスの実行単位です。たとえば 360 の PC 最適化、トロイの木馬スキャンなどの機能です。
役割:効率を高める。
注意:二つの
プロセスのメモリは独立しており共有されない。Java 言語では、二つのスレッドのヒープメモリとメソッド領域メモリは共有されるが、スタックメモリは独立している。
考察:マルチスレッドを使った後、main メソッドが終了しても、プログラムが終了しない可能性がある。main メソッドの終了は主スレッドの終了を意味するだけであり、主スタックが空になっても、他のスタック(スレッド)がまだ存在する可能性がある。
並行と並列
- 並行:同じ時刻に、複数の命令が単一 CPU 上で
交互に実行される - 並列:同じ時刻に、複数の命令が複数 CPU 上で
同時に実行される
実装方式
Threadクラスを継承し、runメソッドをオーバーライドするRunnableインターフェースを実装するCallableインターフェースとFutureインターフェースを使う
方法三では、マルチスレッドの実行結果を取得できる。
方式一
//新しいクラスを作成し、Thread クラスを継承する
public class OneThread extends Thread{
//Run メソッドをオーバーライドする
public void run(){
//マルチスレッドで実行したいコード
}
}
class Test{
public static void main(String[] args){
//新しく作成したクラスのインスタンスを作る
OneThread t = new OneThread();
//スレッドを開始する
t.start();
//複数のスレッドを使いたい場合は、複数のインスタンスオブジェクトを作るだけでよい
OneThread t1 = new OneThread();
OneThread t2 = new OneThread();
t1.start();
t2.start();
}
}注意:start() メソッドの役割は、分岐スレッドを起動し、JVM 内に新しいスタック領域を確保することです。このコードのタスク自体は瞬時に終了します。起動に成功したスレッドは自動的に run() メソッドを呼び出し、run メソッドは分岐スタックのスタック底部に入ります。
mainメソッドは主スタックのスタック底部にあり、runメソッドは分岐スタックのスタック底部にあります。runとmainは同じ階層です。mainメソッド内で直接runメソッドを呼び出すと、通常のメソッド呼び出しと同じであり、新しいスレッドは開かれない。
方式二
//新しいクラスを作成し、Runnable インターフェースを実装する
public class MyThread implements Runnable{
//run メソッドを実装する
public void run(){
//マルチスレッドで実行したいコード
}
}
class Test{
public static void main(String[] args){
MyThread mt = new MyThread();
Thread t = new Thread(mr);
//スレッドを開始する
t.start();
}
}匿名内部クラスの方式も使える。
class Test{
public static void main(String[] args){
Thread t = new Thread(new Runable(){
@Override
public void run(){
//別スレッドで実行したいコード
}
});
//スレッドを開始する
t.start();
}
}方式三
//新しいクラスを作成し、Callable インターフェースを実装する
//ここでのジェネリクスは結果の型であり、ここでは整数型を返す例にする
public class MyCallable implements Callable<Integer>{
//Callable の call メソッドをオーバーライドする
public Integer call() throws Exception {
//マルチスレッドで実行したいコード
int number = 1;
return number;
}
}
class{
public static void main(String[] args) throw Exception{
//MyCallable のインスタンスを作成する
MyCallable mc = new MyCallable();
//FutureTask のインスタンスを作成し、マルチスレッド実行結果を管理する
FutureTask<Integer> ft = new FutureTask<>(mc);
//スレッドオブジェクトを作成する
Thread t1 = new Thread(ft);
//スレッドを開始する
t1.start();
//マルチスレッド実行結果を取得する
int result= ft.get();
}
}Thread クラスのメンバメソッド
| 基本メソッド | 説明 |
|---|---|
| String getName() | スレッド名を取得する |
| void setName() | スレッド名を設定する。コンストラクタでも名前を設定できる |
| static Thread currentThread() | 現在のスレッドオブジェクトを取得する |
| static void sleep(Long time) | 指定した時間 ms だけスレッドを休眠させる |
スレッドのデフォルト名:
Thread-0、Thread-1...
優先度メソッド
Java ではプリエンプティブスケジューリングを採用しており、すべてのスレッドはランダムに実行される。
| 優先度メソッド | 説明 |
|---|---|
| setPriority(int newPriority) | スレッドの優先度を設定する |
| final int getProiority() | スレッドの優先度を取得する |
Java のスレッド優先度の最小値は
1、最大値は10。代入していなければデフォルトは5です。
デーモンスレッド
final void setDaemon(boolean on)
ture:デーモンスレッドに設定する
非デーモンスレッドの実行が終了すると、デーモンスレッドも順に終了する。コードブロックがまだ実行し終わっていなくても終了する。
割り込み挿入スレッド
public final void join()
このメソッドを使ったスレッドを、現在のメソッドの前に挿入する。
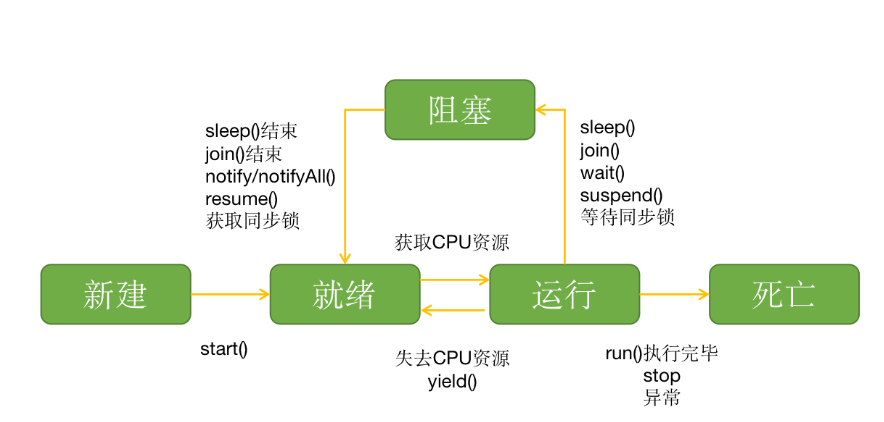
スレッドのライフサイクル
- スレッドオブジェクトを作成した直後の
新規状態 - 実行権を奪い合っている
実行可能状態 - 実行権を獲得した
実行状態 sleepまたは他のブロッキングメソッドに遭遇したブロック状態- スレッド内のコード実行が完了した後の
死亡状態
注意:
- スレッドは
実行中に他のスレッドに実行権を奪われる可能性があり、その場合は実行可能状態に戻る - ブロック状態が終了すると、スレッドは実行可能状態に戻り、再び実行権を奪い合う
同期コードブロック
Java では、スレッドは実行中のどの時点でも実行権を奪われる可能性がある。あるステップを完了するまでそのスレッドから実行権を奪われないようにしたい場合、ロック を使ってこのスレッドを「ロック」できる。
形式:
synchronized (ロックオブジェクト){
共有データを操作するコード
}注意:ロックオブジェクトは必ず一意でなければならない。通常は現在クラスのバイトコードファイルオブジェクト、たとえば
MyThread.classを使う。
特徴:
- ロックはデフォルトで開いている。一つのスレッドが入るとロックは自動的に閉じる
- 中のコードがすべて実行され、スレッドが出た後にロックは自動的に開く
面接問題
public class ThreadTest {
public static void main(String[] args) {
MyThread t = new MyThread();
t.start();
try {
//ここでは t スレッドを 5s 休眠させるのか
t.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Hello World!");
}
}
class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println("T ---> " + i);
}
}
}答えは、主スレッドが 5 秒休眠する、です。sleep メソッドは静的メソッドなので、オブジェクトを通じて呼び出すべきではありません。
このコードには、Thread クラスの sleep メソッドの使い方に関するよくある誤解があります。main メソッド内で t.sleep(5000); を呼び出そうとしていますが、ここでの t は MyThread クラスのインスタンスです。MyThread は Thread クラスの子クラスです。しかし、sleep メソッドは Thread クラスの静的メソッドです。そのため、本来は Thread クラスのインスタンスではなく、クラス名を通じて直接呼び出すべきです。
正しい呼び出し方式は Thread.sleep(5000); であり、この場合、現在実行中のスレッド(この文脈では主スレッド)を 5 秒休眠させる。