
RAG
概念
1. 什么是RAG
RAG = 检索(Retrieval) + 生成(Generation) 它解决一个问题:大模型不知道你公司/个人的私有知识。
办法:先从你的文档里找相关内容,再让大模型根据这些内容回答。
2. RAG是怎么工作的
- 你问问题 → “公司的年假政策是什么?”
- 系统从你的文档中找出最相关的几段话
- 把问题 + 找到的段落一起喂给大模型 → 生成准确答案
基础流程Demo
使用Python来完成一个本地RAG(只需要四个库)
txt
pip install langchain langchain-openai langchain-community chromadb准备“知识库”(一堆文档),例如:policy.txt
tex
员工工作满1年,可享受5天带薪年假。
工作满3年,年假增加至10天。
年假不可跨年累计。完整代码:
python
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# === 1. 加载你的文档 ===
loader = TextLoader("policy.txt", encoding="utf-8")
docs = loader.load()
# === 2. 切分文本 ===
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(docs)
# === 3. 向量化并存入本地数据库 ===
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(
api_key="你的API_KEY",
base_url="https://open.bigmodel.cn/api/paas/v4" # 如果用智谱
# base_url="https://api.openai.com/v1" # 如果用 OpenAI
)
)
# === 4. 构建检索器 ===
retriever = vectorstore.as_retriever()
# === 5. 构建 Prompt 模板 ===
template = """你是一个HR助手,请根据以下上下文回答问题:
{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
# === 6. 调用大模型 ===
llm = ChatOpenAI(
model="glm-4.7-flash",
api_key="你的API_KEY",
base_url="https://open.bigmodel.cn/api/paas/v4"
)
# === 7. 组装 RAG 链(LCEL 写法)===
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# === 8. 提问!===
answer = rag_chain.invoke("工作满2年有多少天年假?")
print(answer)原理图
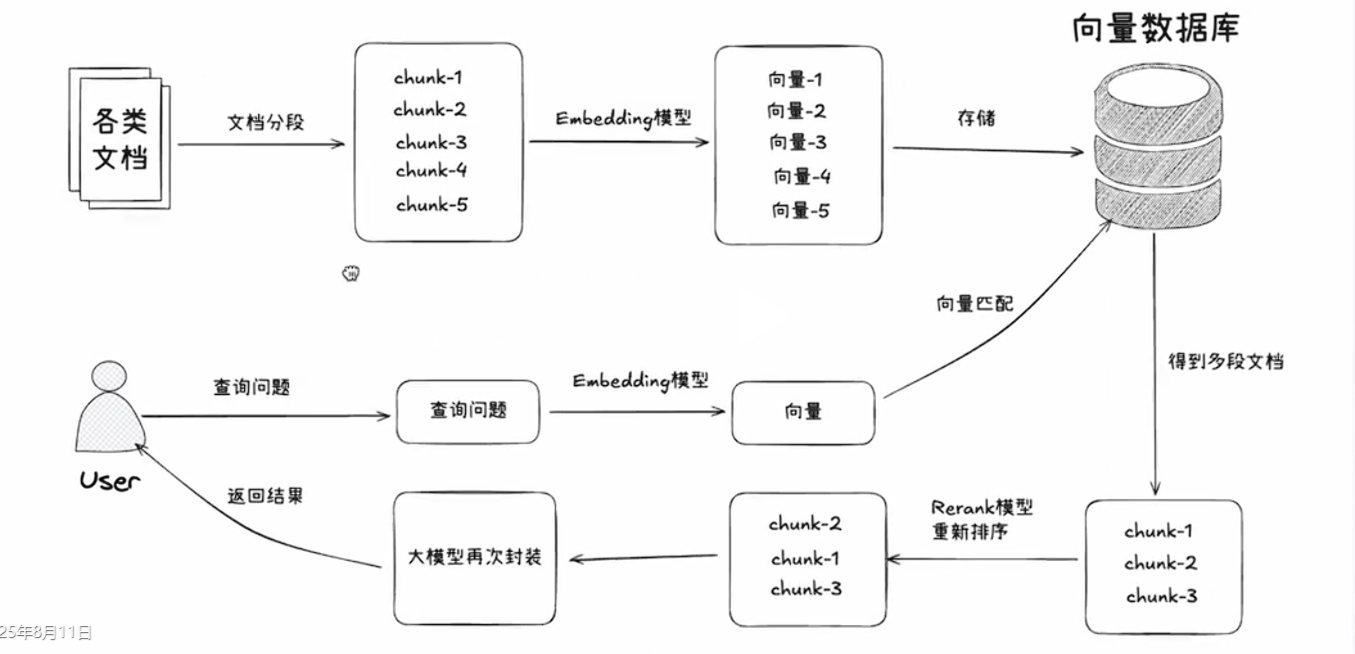 总结流程就是:
总结流程就是:
- 文档 → 切块 → 向量化 → 存起来(Chroma 是本地向量库)
- 提问时,先检索相关段落,再交给大模型
- 整个流程用 LangChain 的 LCEL 一行链式拼接